
本案例来自两年前深圳某客户两节点rac的一次生产故障,现象是大面积的gc buffer busy acquire导致业务瘫痪。
首先查看1节点awr头部信息和load profile

得到的关键信息点:
- 对于LCPU 256的系统,AAS=13379.42/59.91=223,说明系统非常繁忙或者遇到了异常等待。
- sessions异常增长好几倍,DB CPU/DB Time占比非常低,说明是遇到了异常等待。
- 其余指标都还算正常。
既然是遇到异常等待,那么就看看top event部分
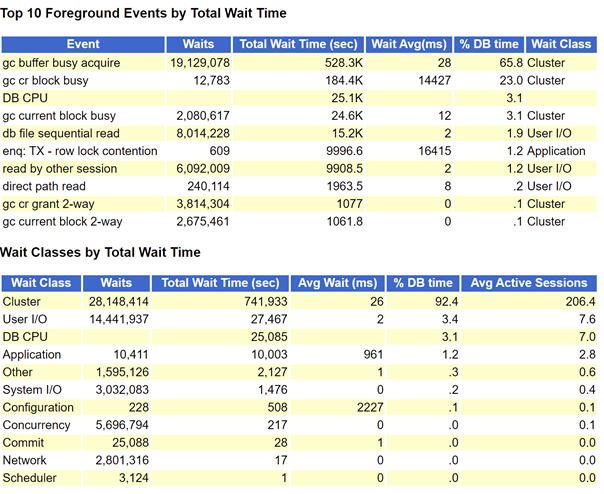
可以看到大量的wait class为Cluster的session,top event也看到大量的gc buffer busy acquire等待事件,该等待事件非常常见就不单独解释了,粗略计算cluster等待事件占据了dbtime的90%左右。
当遇到大量Cluster 等待事件的时候,必须先看看RAC Statistics

可以看到每秒传输的block以及message都不多,流量也并不大,所以完全没有必要去查看SQL ordered by Cluster Wait Time部分,继续往下看发现Avg global cache cr block receive time (ms)过高,达到了1473ms。判断此次大量的cluster等待是由于接受远端实例发送cr block过慢导致。
|
1 |
gc cr block receive time = gc cr block (flush time + build time + send time) |
从公式可以看出是远端实例的 gc cr block flush time /build time/send time出现了问题,所以此时需要去看看2节点的awr的RAC Statistics
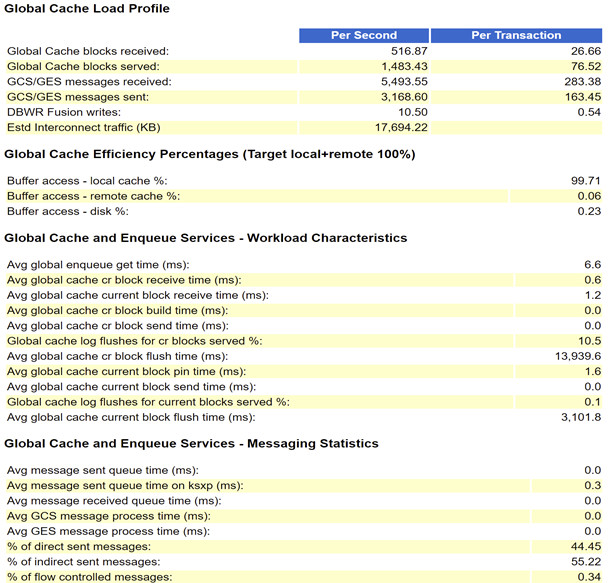
可以看到Avg global cache cr block flush time (ms)非常高,关于current block flush redo的行为有很多的介绍,这里就不解释了。对于cr block flush redo的行为,通常在需要从远端实例的current block构造cr block时才会产生。关于构造cr块产生redo的问题后续会专门写一篇文章解释,不是本案例的重点。
Normally CR block buffer processing does not include the ‘gc cr block flush time’. However, when a CR buffer is cloned from a current buffer that has redo pending, a log flush for a CR block transfer is required. A high percentage is indicative of hot blocks with frequent read after write access.
对于current/cr flush time延迟较高,通常有两种可能:
- lgwr写性能差
- lgwr被阻塞
所以下一步思路是直接去看看2节点awr的Background Wait Events和Wait Event Histogram查看lgwr的写性能如何,是否稳定。
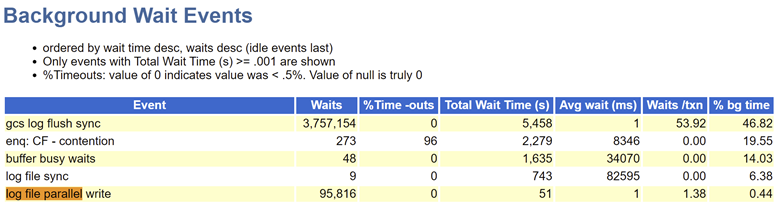

可以看到2节点lgwr写性能非常稳定,并且延迟也正常。那么就不是lgwr写性能的问题,很有可能是lgwr被阻塞。

通过top event看到了2节点有大量等待是等待日志切换完成,说明确实LGWR遭到了阻塞,这个时候是时候去分析ash了,可以直接过滤其他信息去单独查看lgwr的ash信息。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
SQL> select to_char(sample_time,'yyyy-mm-dd hh24:mi:ss'),program,session_id,event,seq#,BLOCKING_SESSION,BLOCKING_INST_ID from m_ash where program like '%LGWR%' and inst_id=2 order by 1; TO_CHAR(SAMPLE_TIME PROGRAM SESSION_ID EVENT SEQ# BLOCKING_SESSION BLOCKING_INST_ID ------------------- ------------------------------ ---------- ------------------------------ ---------- ---------------- ---------------- ... 2020-03-07 15:44:40 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:41 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:42 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:43 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:44 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:45 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:46 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:47 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:48 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:49 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:50 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:51 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:52 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:53 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:54 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:55 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:56 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:57 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 2020-03-07 15:44:58 oracle@sxdb02 (LGWR) 913 enq: CF - contention 3850 2224 1 ... |
可以看到从 15:44:40 开始,lgwr就开始等待CF队列,并且一直持续非常长的时间,阻塞会话是节点1的sid为2224的会话。结合之前awr的分析这里猜测是在 15:44:40 进行了日志切换,因为日志切换需要去读取控制文件。那么下面看看blocking session的信息。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
SQL> select to_char(sample_time,'yyyy-mm-dd hh24:mi:ss'),program,session_id,event,seq#,BLOCKING_SESSION,BLOCKING_INST_ID from m_ash where session_id=2224 and inst_id=1 order by 1; TO_CHAR(SAMPLE_TIME PROGRAM SESSION_ID EVENT SEQ# BLOCKING_SESSION BLOCKING_INST_ID ------------------- ------------------------- ---------- ------------------------------ ---------- ---------------- ---------------- ... 2020-03-07 15:37:41 oracle@sxdb01 (M000) 2224 control file sequential read 479 2020-03-07 15:37:42 oracle@sxdb01 (M000) 2224 566 2020-03-07 15:37:43 oracle@sxdb01 (M000) 2224 control file sequential read 632 2020-03-07 15:37:44 oracle@sxdb01 (M000) 2224 control file sequential read 684 2020-03-07 15:37:45 oracle@sxdb01 (M000) 2224 736 2020-03-07 15:37:46 oracle@sxdb01 (M000) 2224 781 2020-03-07 15:37:47 oracle@sxdb01 (M000) 2224 824 2020-03-07 15:37:48 oracle@sxdb01 (M000) 2224 865 2020-03-07 15:37:49 oracle@sxdb01 (M000) 2224 915 2020-03-07 15:37:50 oracle@sxdb01 (M000) 2224 1031 2020-03-07 15:37:51 oracle@sxdb01 (M000) 2224 1183 2020-03-07 15:37:52 oracle@sxdb01 (M000) 2224 control file sequential read 1304 2020-03-07 15:37:53 oracle@sxdb01 (M000) 2224 1400 2020-03-07 15:37:54 oracle@sxdb01 (M000) 2224 1481 2020-03-07 15:37:55 oracle@sxdb01 (M000) 2224 control file sequential read 1631 2020-03-07 15:37:56 oracle@sxdb01 (M000) 2224 control file sequential read 1834 2020-03-07 15:37:57 oracle@sxdb01 (M000) 2224 control file sequential read 1947 2020-03-07 15:37:58 oracle@sxdb01 (M000) 2224 control file sequential read 2052 2020-03-07 15:37:59 oracle@sxdb01 (M000) 2224 control file sequential read 2159 2020-03-07 15:38:00 oracle@sxdb01 (M000) 2224 control file sequential read 2269 2020-03-07 15:38:01 oracle@sxdb01 (M000) 2224 control file sequential read 2404 2020-03-07 15:38:02 oracle@sxdb01 (M000) 2224 control file sequential read 2517 2020-03-07 15:38:03 oracle@sxdb01 (M000) 2224 control file sequential read 2672 2020-03-07 15:38:04 oracle@sxdb01 (M000) 2224 2801 2020-03-07 15:38:05 oracle@sxdb01 (M000) 2224 2857 2020-03-07 15:38:06 oracle@sxdb01 (M000) 2224 2866 2020-03-07 15:38:07 oracle@sxdb01 (M000) 2224 control file sequential read 2893 2020-03-07 15:38:08 oracle@sxdb01 (M000) 2224 3007 2020-03-07 15:38:09 oracle@sxdb01 (M000) 2224 control file sequential read 3111 2020-03-07 15:38:10 oracle@sxdb01 (M000) 2224 3184 2020-03-07 15:38:11 oracle@sxdb01 (M000) 2224 control file sequential read 3218 2020-03-07 15:38:12 oracle@sxdb01 (M000) 2224 control file sequential read 3263 2020-03-07 15:38:13 oracle@sxdb01 (M000) 2224 3304 .. |
这里看到阻塞进程为1节点的M000,从15:37分就开始持有CF锁一直在读取控制文件,持续了非常久的时间,导致2节点日志切换时,2节点LGWR无法持有CF锁。M000为MMON进程的slave进程,关于MMON进程我们知道通常都是跟awr有关,为什么会不断的读取控制文件呢?
结合diag产生的systemstate dump里去查看M000的short_stack信息
Short stack dump: ksedsts()+380<-ksdxfstk()+52<-ksdxcb()+3592<-sspuser()+140<-__sighndlr()+12<-call_user_handler()+868<-sigacthandler()+92<-__pread()+12<-pread()+112<-skgfqio()+532<-ksfd_skgfqio()+756<-ksfd_io()+676<-ksfdread()+640<-kfk_ufs_sync_io()+416<-kfk_submit_io()+260<-kfk_io1()+916<-kfk_transitIO()+2512<-kfioSubmitIO()+408<-kfioRequestPriv()+220<-kfioRequest()+472<-ksfd_kfioRequest()+444<-ksfd_osmio()+2956<-ksfd_io()+1868<-ksfdread()+640<-kccrbp()+496<-kccrec_rbl()+296<-kccrec_read_write()+1680<-kccrrc()+1072<-krbm_cleanup_map()+28<-kgghstmap()+92<-krbm_cleanup_backup_records()+1100<-kraalac_slave_action()+1016<-kebm_slave_main()+744<-ksvrdp()+1928<-opirip()+1972<-opidrv()+748<-sou2o()+88<-opimai_real()+512<-ssthrdmain()+324<-main()+316<-_start()+380
kraalac_slave_action ->krbm_cleanup_backup_records-> krbm_cleanup_map -> kccrrc ,这里可以看到M000当时在清理备份记录而去读取的控制文件,从M000 trace或者ash里M000的action name可以看到当时m000的action为Monitor FRA Space,说明是MMON发起slave去做Monitor FRA Space,而FRA空间不足所以触发的清理一些FRA里的备份记录从而读取的控制文件。
知道了M000为何要去读取控制文件,那么下一个问题就是为什么会读那么久呢?控制文件过大?控制文件读取过慢?还是从systemstate dump中找到了答案
|
1 2 3 4 5 6 |
SO: 0x22e13908e0, type: 10, owner: 0x23012ace68, flag: INIT/-/-/0x00 if: 0x1 c: 0x1 proc=0x23012ace68, name=FileOpenBlock, file=ksfd.h LINE:6688 ID:, pg=0 (FOB) 22e13908e0 flags=2560 fib=22fde0d288 incno=0 pending i/o cnt=0 fname=+FASTDG/sxboss/controlfile/current.256.907844431 fno=1 lblksz=16384 fsiz=118532 |
控制文件大小为 lblksz* fsiz=16384*118532=1.8g,为何控制文件会那么大呢?

因为control_file_record_keep_time设置为了365天。
解决方案:
- 1.根据备份策略合理设置 control_file_record_keep_time
- 2.重建控制文件
该案例得到的收获就是平时对MMON进程的作用了解过少,通过KST trace跟踪MMON,发现MMON的作用非常非常多,并不只是与AWR相关。KST trace跟踪到的MMON的action如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
(MMON) : (infrequent action) : acnum=[133] comment=[deferred controlfile autobackup action] (MMON) : (infrequent action) : acnum=[150] comment=[recovery area alert action] (MMON) : (infrequent action) : acnum=[167] comment=[undo usage] (MMON) : (infrequent action) : acnum=[171] comment=[Block Cleanout Optim, Undo Segment Scan] (MMON) : (infrequent action) : acnum=[175] comment=[Flashback Archive RAC Health Check] (MMON) : (infrequent action) : acnum=[178] comment=[tune undo retention lob] (MMON) : (infrequent action) : acnum=[179] comment=[MMON Periodic LOB MQL Selector] (MMON) : (infrequent action) : acnum=[180] comment=[MMON Periodic LOB Spc Analyze ] (MMON) : (infrequent action) : acnum=[183] comment=[tablespace alert monitor] (MMON) : (infrequent action) : acnum=[197] comment=[OLS Cleanup] (MMON) : (infrequent action) : acnum=[205] comment=[Sample Shared Server Activity] (MMON) : (infrequent action) : acnum=[212] comment=[Compute cache stats in background] (MMON) : (infrequent action) : acnum=[213] comment=[SPM: Auto-purge expired SQL plan baselines] (MMON) : (infrequent action) : acnum=[214] comment=[SPM: Check SMB size] (MMON) : (infrequent action) : acnum=[215] comment=[SPM: Delete excess sqllog$ batches] (MMON) : (infrequent action) : acnum=[219] comment=[KSXM Advance DML Frequencies] (MMON) : (infrequent action) : acnum=[220] comment=[KSXM Broadcast DML Frequencies] (MMON) : (infrequent action) : acnum=[225] comment=[Cleanup client cache server state in background] (MMON) : (infrequent action) : acnum=[226] comment=[MMON TSM Cleanup] (MMON) : (infrequent action) : acnum=[296] comment=[alert message cleanup] (MMON) : (infrequent action) : acnum=[297] comment=[alert message purge] (MMON) : (infrequent action) : acnum=[298] comment=[AWR Auto Flush Task] (MMON) : (infrequent action) : acnum=[299] comment=[AWR Auto Purge Task] (MMON) : (infrequent action) : acnum=[300] comment=[AWR Auto DBFUS Task] (MMON) : (infrequent action) : acnum=[301] comment=[AWR Auto CPU USAGE Task] (MMON) : (infrequent action) : acnum=[305] comment=[Advisor delete expired tasks] (MMON) : (infrequent action) : acnum=[313] comment=[run-once action driver] (MMON) : (infrequent action) : acnum=[319] comment=[metrics monitoring] (MMON) : (infrequent action) : acnum=[322] comment=[sql tuning hard kill defense] (MMON) : (infrequent action) : acnum=[323] comment=[autotask status check] (MMON) : (infrequent action) : acnum=[324] comment=[Maintain AWR Baseline Thresholds Task] (MMON) : (infrequent action) : acnum=[325] comment=[WCR: Record Action Switcher] (MMON) : (infrequent action) : acnum=[331] comment=[WCR: Replay Action Switcher] (MMON) : (infrequent action) : acnum=[338] comment=[SQL Monitoring Garbage Collector] (MMON) : (infrequent action) : acnum=[344] comment=[Coordinator autostart timeout] (MMON) : (infrequent action) : acnum=[348] comment=[ADR Auto Purge Task] (MMON) : (infrequent action) : acnum=[41] comment=[reload failed KSPD callbacks] (MMON) : (infrequent action) : acnum=[75] comment=[flashcache object keep monitor] (MMON) : (interrupt action) : acnum=[108] comment=[Scumnt mount lock] (MMON) : (interrupt action) : acnum=[109] comment=[Poll system events broadcast channel] (MMON) : (interrupt action) : acnum=[20] comment=[KSB action for ksbxic() calls] (MMON) : (interrupt action) : acnum=[2] comment=[KSB action for X-instance calls] (MMON) : (interrupt action) : acnum=[306] comment=[MMON Remote action Listener] (MMON) : (interrupt action) : acnum=[307] comment=[MMON Local action Listener] (MMON) : (interrupt action) : acnum=[308] comment=[MMON Completion Callback Dispatcher] (MMON) : (interrupt action) : acnum=[309] comment=[MMON set edition interrupt action] (MMON) : (interrupt action) : acnum=[341] comment=[Check for sync messages from other instances] (MMON) : (interrupt action) : acnum=[343] comment=[Check for autostart messages from other instances] (MMON) : (interrupt action) : acnum=[350] comment=[Process staged incidents] (MMON) : (interrupt action) : acnum=[351] comment=[DDE MMON action to schedule async action slaves] (MMON) : (interrupt action) : acnum=[39] comment=[MMON request for RLB metrics] (MMON) : (requested action) : acnum=[314] comment=[shutdown MMON] (MMON) : (requested action) : acnum=[315] comment=[MMON DB open] (MMON) : (requested action) : acnum=[321] comment=[ADDM (KEH)] (MMON) : (requested action) : acnum=[347] comment=[Job Autostart action force] (MMON) : (requested action) : acnum=[349] comment=[Schedule slave to update incident meter] (MMON) : (requested action) : acnum=[63] comment=[SGA memory tuning parameter update] (MMON) : (timeout action) : acnum=[0] comment=[Monitor Cleanup] (MMON) : (timeout action) : acnum=[11] comment=[Update shared pool advice stats] (MMON) : (timeout action) : acnum=[154] comment=[Flashback Marker] (MMON) : (timeout action) : acnum=[172] comment=[Block Cleanout Optim, Rac specific code] (MMON) : (timeout action) : acnum=[173] comment=[BCO:] (MMON) : (timeout action) : acnum=[1] comment=[Update KGSTM Translation] (MMON) : (timeout action) : acnum=[3] comment=[KSB action for bast checking] (MMON) : (timeout action) : acnum=[42] comment=[reconfiguration MMON action] (MMON) : (timeout action) : acnum=[63] comment=[SGA memory tuning parameter update] (MMON) : (timeout action) : acnum=[69] comment=[SGA memory tuning] 。。。 |
大概有几百种action,平时对MMON关注还是太少了。