
本案例是福建某客户一套待上线系统,操作系统版本为AIX 7.2 ,集群版本为12.2。几天前2节点GI突然重启,由于是比较重要的待上线系统,所以需要仔细一下分析原因。
话不多说,由于是GI突然重启,那么先看看GI alert日志:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
2021-11-09 21:21:57.050 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:00.066 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:03.070 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:05.093 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:05.151 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:06.081 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:06.093 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:06.100 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:06.105 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:06.109 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:09.091 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:12.097 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:15.100 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:18.105 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:21.109 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:24.113 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:27.118 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:30.122 [GPNPD(7537210)]CRS-2340: Errors occurred while processing received gpnp message. 2021-11-09 21:22:33.126 [OHASD(22348120)]Can't find message for prod[CRS], fac[CRS], and msg id [2119] 2021-11-09 21:22:33.130 [ORAAGENT(17629684)]CRS-5822: Agent '/app/grid/product/12.2.0/grid/bin/oraagent_grid' disconnected from server. Details at (:CRSAGF00117:) {0:2:1632} in /app/grid/base/diag/crs/p1bemdg2/crs/trace/ohasd_oraagent_grid.trc. 2021-11-09 21:22:33.130 [CSSDMONITOR(13042246)]CRS-5822: Agent '/app/grid/product/12.2.0/grid/bin/cssdmonitor_root' disconnected from server. Details at (:CRSAGF00117:) {0:3:21405} in /app/grid/base/diag/crs/p1bemdg2/crs/trace/ohasd_cssdmonitor_root.trc. 2021-11-09 21:22:33.130 [ORAROOTAGENT(38535474)]CRS-5822: Agent '/app/grid/product/12.2.0/grid/bin/orarootagent_root' disconnected from server. Details at (:CRSAGF00117:) {0:1:1420} in /app/grid/base/diag/crs/p1bemdg2/crs/trace/ohasd_orarootagent_root.trc. 2021-11-09 21:22:33.130 [CSSDAGENT(14418484)]CRS-5822: Agent '/app/grid/product/12.2.0/grid/bin/cssdagent_root' disconnected from server. Details at (:CRSAGF00117:) {0:4:21329} in /app/grid/base/diag/crs/p1bemdg2/crs/trace/ohasd_cssdagent_root.trc. |
可以看到从21点21分开始出现gpnp通信异常,22分33秒时ohasd栈的4个agent全部同时挂掉,这其实给了我们很大的提示,ohasd_orarootagent_root、ohasd_oraagent_grid、ohasd_orarootagent_root、ohasd_cssdagent_root正好是ohasd.bin守护进程启动之后启动的4个agent,它们负责维护(启动、关闭等等)ohasd层面的资源,如果出现同时挂掉的话,那么大概率是ohasd.bin出现了异常crash掉了,所以下一步直接看ohasd的trace文件。
|
1 2 3 4 5 6 7 8 9 10 11 |
2021-11-09 21:21:50.060 : OCRUTL:3085: prou_add_log_list_int:proath_new_entry is NULL for 2021-11-09 21:21:50.060: th_process_request: Completed op [13] return [12] 2021-11-09 21:21:50.060 : OCRSRV:3085: th_select_w_f_r: Error processing request [12] 2021-11-09 21:21:50.060 : OCRUTL:3085: u_allocm: metactx [111a7c2d0], ptr returned is NULL, size to lmmcalloc [1040] 2021-11-09 21:21:50.060 : OCRUTL:3085: prou_add_log_list_int:proath_new_entry is NULL for 2021-11-09 21:21:50.060: th_select_w_f_t: Processed request constr [0000000000000069] retval [12] 2021-11-09 21:21:57.032 : OCRUTL:3342: u_allocm: metactx [111a7c2d0], ptr returned is NULL, size to lmmcalloc [4120] OCRSRV:3342: proas_get_value: Failure is malloc [12] OCRAPI:2828: SLOS : SLOS: cat=-2, opn=malloc, dep=12, loc=addgrpnm1 unable to add group (system) OCRUTL:2828: u_fill_errorbuf: Error Info : [[SLOS: cat=-2, opn=malloc, dep=12, loc=addgrpnm1 unable to add group (system) |
从gpnpd出现异常的时间点,可以看到ohasd动态分配4120的内存失败,从gipcd.trc也可以看出通信异常的原因也是无法分配内存.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
2021-11-09 21:21:57.034 : OCRCLI:1286: proac_get_value:[SYSTEM.GPnP.profiles.peer.best]: Response message failed [12] 2021-11-09 21:21:57.034 : OCRAPI:1286: a_read: failed to read key [12] 2021-11-09 21:21:57.034 : GPNP:1286: procr_get_value_ext: OLR api procr_get_value_ext failed for key SYSTEM.GPnP.profiles.peer.best 2021-11-09 21:21:57.034 : GPNP:1286: procr_get_value_ext: OLR current boot level : 7 2021-11-09 21:21:57.034 : GPNP:1286: procr_get_value_ext: OLR error code : 12 2021-11-09 21:21:57.034 : GPNP:1286: procr_get_value_ext: OLR error message : PROCL-12: Out of heap memory. 2021-11-09 21:21:57.034 : GPNP:1286: clsgpnp_getProfileEx: [at clsgpnp.c:602] Result: (2) CLSGPNP_MEMORY. (:GPNP00140:) get cache profile failed, will try gpnpd call 2021-11-09 21:21:57.045 : OCRCLI:1286: proac_get_value:[SYSTEM.version.activeversion]: Response message failed [12] 2021-11-09 21:21:57.045 : OCRAPI:1286: a_read: failed to read key [12] default:1286: Failure 12 in trying to get AV value SYSTEM.version.activeversion default:1286: procr_get_value error 12 errorbuf : PROCL-12: Out of heap memory. |
继续往下看ohasd的trace
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
2021-11-09 21:22:18.103 : OCRUTL:2571: prou_add_log_list_int:proath_new_entry is NULL for 2021-11-09 21:22:18.102: th_select_w_f_t: Processed request constr [0000000000000069] retval [0] OCRAPI:3342: SLOS : SLOS: cat=-2, opn=malloc, dep=12, loc=addgrpnm1 unable to add group (system) OCRUTL:3342: u_fill_errorbuf: Error Info : [[SLOS: cat=-2, opn=malloc, dep=12, loc=addgrpnm1 unable to add group (system) ]] 2021-11-09 21:22:18.103 : OCRUTL:2828: u_allocm: metactx [111a7c2d0], ptr returned is NULL, size to lmmcalloc [4120] OCRSRV:2828: proas_get_value: Failure is malloc [12] 2021-11-09 21:22:18.104 : OCRUTL:3085: u_allocm: metactx [111a7c2d0], ptr returned is NULL, size to lmmcalloc [4120] OCRSRV:3085: proas_get_value: Failure is malloc [12] 2021-11-09 21:22:18.104 : OCRSRV:2571: proas_cache_locked: Value not cached for key [SYSTEM.network] : retval [84] OCRAPI:3342: SLOS : SLOS: cat=-2, opn=malloc, dep=12, loc=addgrpnm1 unable to add group (system) OCRUTL:3342: u_fill_errorbuf: Error Info : [[SLOS: cat=-2, opn=malloc, dep=12, loc=addgrpnm1 unable to add group (system) ]] 2021-11-09 21:22:18.105 : OCRUTL:3085: u_allocm: metactx [111a7c2d0], ptr returned is NULL, size to lmmcalloc [4120] OCRSRV:3085: proas_get_value: Failure is malloc [12] 2021-11-09 21:22:18.107 : OCRUTL:2571: u_allocm: metactx [111a7c2d0], ptr returned is NULL, size to lmmcalloc [280] 2021-11-09 21:22:18.107 : OCRRAW:2571: prcreatei: could not allocate memory 3 ... 2021-11-09 21:22:33.126 : OCRUTL:2571: u_allocm: metactx [111a7c2d0], ptr returned is NULL, size to lmmcalloc [4120] OCRSRV:2571: proas_get_value: Failure is malloc [12] 2021-11-09 21:22:33.126 :GIPCXCPT:2057: gipclibMalloc: failed to allocate 40960 bytes, cowork 11234c978, ret gipcretOutOfMemory (28) 2021-11-09 21:22:33.126 : OCRUTL:2828: u_allocm: metactx [111a7c2d0], ptr returned is NULL, size to lmmcalloc [4120] OCRSRV:2828: proas_get_value: Failure is malloc [12] 2021-11-09 21:22:33.126 :GIPCXCPT:2057: gipcWaitF [prom_select : prom.c : 4591]: EXCEPTION[ ret gipcretOutOfMemory (28) ] failed to wait on obj 112592dd0 [000000000000002a] { gipcContainer : numObj 11, wobj 1125933b0, objFlags 0x0 }, reqList 11234d420, nreq 1, creq 11234d4e8 timeout INFINITE, flags 0x0 2021-11-09 21:22:33.126 : OCRUTL:2828: u_allocm: metactx [111a7c2d0], ptr returned is NULL, size to lmmcalloc [1040] 2021-11-09 21:22:33.126 : OCRMSG:2057: prom_select: Failed to wait on container [28] 2021-11-09 21:22:33.126 : OCRUTL:2828: prou_add_log_list_int:proath_new_entry is NULL for 2021-11-09 21:22:33.126: prom_send: Before gipcSend 2021-11-09 21:22:33.126 : OCRMSG:2057: GIPC error [28] msg [gipcretOutOfMemory] 2021-11-09 21:22:33.126 : OCRUTL:2571: u_allocm: metactx [111a7c2d0], ptr returned is NULL, size to lmmcalloc [1040] 2021-11-09 21:22:33.126 : OCRUTL:2571: prou_add_log_list_int:proath_new_entry is NULL for 2021-11-09 21:22:33.126: th_select_w_f_t: Processed request constr [0000000000000069] retval [0] 2021-11-09 21:22:33.126 : OCRUTL:2057: u_allocm: metactx [111a7c2d0], ptr returned is NULL, size to lmmcalloc [2088] 2021-11-09 21:22:33.126 : OCRUTL:2057: u_insert_error: Error allocating memory for hashelement. OCRSRV:2057: th_select: Failed to select [24] OCRSRV:2057: th_select: Can no longer process local connections. Setting OCR context to invalid 2021-11-09 21:22:33.126 : OCRAPI:2057: procr_ctx_set_invalid: ctx is in state [10]. 2021-11-09 21:22:33.126 : OCRAPI:2057: procr_ctx_set_invalid: ctx set to invalid 2021-11-09 21:22:33.126 : OCRAPI:2057: procr_ctx_set_invalid: Aborting... Trace file /app/grid/base/diag/crs/p1bemdg2/crs/trace/ohasd.trc Oracle Database 12c Clusterware Release 12.2.0.1.0 - Production Copyright 1996, 2016 Oracle. All rights reserved. CLSB:1: Argument count (argc) for this daemon is 2 CLSB:1: Argument 0 is: /app/grid/product/12.2.0/grid/bin/ohasd.bin CLSB:1: Argument 1 is: restart |
可以看到大量的内存分配失败之后,ohasd.bin被abort了,这就是导致GI重启的原因。由于ohasd.bin是root来维护的,所以查看一下root的ulimit
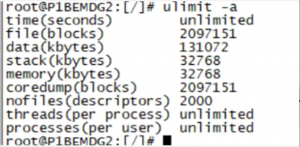
这里可以看到大量错误的设置,包括导致此次故障的memory limit。