
本案例来自西区某银行,使用的是19c的gi,11g的db,据现场同事反馈ASM磁盘组datac1 在还有空间的情况下,数据文件无法自动扩展,报错ORA-15041。
该磁盘组基本情况如下:
- 磁盘组总容量250T,由144块1.7T 的磁盘组成
- 3个failgroup、high冗余
|
1 2 3 4 |
[oracle@rac1 ~]$ oerr ora 15041 15041, 00000, "diskgroup \"%s\" space exhausted" // *Cause: The diskgroup ran out of space. // *Action: Add more disks to the diskgroup, or delete some existing files. |
ORA-15041还是比较常见的错误,MOS上有一篇文档ORA-15041 Diskgroup Space Exhausted (Doc ID 1367078.1) 对该错误有比较详细的描述以及诊断思路。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
Cause: The error is seen when allocation units was allocated/moved in diskgroup. During this operation, ASM consider the size of the disks and the ASM file size getting those allocations. If any one disk not able to satisfy the allocation will result in the error. There is ASM Metadata discrepancy There is ongoing rebalance operation and/or disk(s) not in CACHED/MEMBER status. There are offline disks. Solution o The first thing you should check if there is any ongoing rebalance. Query gv$asm_operation. If this is going on then allow this to complete. Check the ASM alert.log file(s) as well. If the rebalance encountered error for any reason, the following points should help completing this. o Query v$asm_disk.total_mb and free_mb for each disk in the diskgroup. If any one disk is short of free_mb, then the error might be seen, even if there is sufficient free space in the whole diskgroup. o This is a must that you have all the disks of same size, in a diskgroup. Starting 10.2, the total size of the disk is taken into consideration for allocations. So there will be imbalanced IO to disks. A future task would be to add/drop disks to have all the disks of same size. 1] Check if there is real shortage of space in the diskgroup. Check all the disks have similar v$asm_disk,total_mb and free_mb values. Then we need to add disk(s) to the diskgroup. You can use MOS Doc ID 351117.1 to get theh detailed space utilization, both from ASM side and RDBMS side. 2] Even after a successful completion of manual rebalance, and with sufficient v$asm_disk.free_mb in each disk, if ORA-15041 is seen then, On the ASM instance: alter diskgroup <diskgroup name> check all norepair; This can be run safely on active system. Once this command completes, check the ASM alert.log if it reports any "mismatch" of AT and DD. Something like NOTE: disk <diskgroup name>, used AU total mismatch: DD=32169, AT=32172 If yes, then run: alter diskgroup <diskgroup name> check all repair; This can be run safely on active system and is meant to fix the AT and DD discrepancy. An AT and DD ASM Metadata discrepancy might manifest because of previous failed file allocation in the diskgroup. After the check all repair command, run a manual rebalance alter diskgroup <diskgroup name> rebalance power <n>; Allow the rebalance to complete, monitor ASM alert.log and gv$asm_operation. Once this is done, query v$asm_disk.free_mb for each disk. NOTE: Checking the free_mb for each disk and periodically running check all norepair on the diskgroup to check AT and DD mismatch can be included in the system monitoring scripts. 3] If any one or more disk in the diskgroup has very less space ( say < 300 MB ), then manual rebalance/add of new disks will not help. Because rebalance operation needs some amount of free space in each disk. Also add of a new disk will invoke an automatic rebalance that will also fail with ORA-15041. In this case, you should look to remove/move some files from the diskgroup. Check for obsolete RMAN/dump files, temp files etc. Once we remove/move some files, from the diskgroup, query v$asm_disk.free_mb for each disk. If the free_mb is say > 300 MB, run a manual rebalance ( or add disk ) alter diskgroup <diskgroup name> rebalance power; 4] If you are on 11gR1 ASM, after considering the above points, refer to MOS Doc ID 813013.1 5] If you are on 11gR2 and a diskgroup has a quorum disk in it, after considering the above points, refer to MOS Doc ID 1379665.1 6] On 11gR2 with high number of disks (e.g more than 200 disks), if successful rebalance is still showing imbalanced space distribution, then there is possibility that Bug 20081450 is encountered. Refer to MOS Doc ID 1980292.1 |
经过分析发现,该磁盘组每个failgroup磁盘状态均正常,并且磁盘个数与磁盘大小均相同,元数据也无异常,但是ASM磁盘组数据分布非常不均衡,大部分磁盘都还剩200G左右空间,但是其中有几块盘,free_mb几乎为0,最大的磁盘free_mb有360G,在这种情况下即便是添加磁盘或者rebalance都是无济于事的,因为rebalance的前提条件是每块盘必须有至少300M的空间。此时只有一个办法就是remove/resize磁盘组的文件释放出一些空间。
当释放的空间满足rebalance之后,手动去执行rebalance发现没有任何作用。设置”_asm_imbalance_tolerance”为0,再次rebalance仍然是涛声依旧。该问题其实风险很大了,因为磁盘组几乎用满,业务增长量也很快,随时有磁盘组容量不足的隐患。
所以还得继续分析,通过sql去查询每个磁盘的最大extent差距和最大au差距
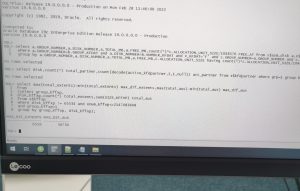
发现free最大的磁盘和最小的磁盘之间有接近6000多个extent差距和56000多个AU差距,并且extent和au差距有接近10倍是因为数据库中大量使用了bigfile,配合11.1引入的asm磁盘组属性variable extent,导致磁盘之间的free_mb差距进一步增大,假如没有bigfile的话,那么该案例即使磁盘组分布不均衡,最多也只是差6000多个AU而已。这也给尽量不使用bigfile再添加上了一个理由。
对于asm rebalance原理,之前有做过深入的分析,结合一下之前分析的结论
可以想到的解决办法是:
- disable variable extent,但是只会对新增文件生效并没有什么用,而且该特性在有bigfile的情况下是非常有用的特性,所以否决掉该方案。
- 剔除一些磁盘新建一个磁盘组,全部使用small file,考虑到该库非常大,并且db是11g的没有online move datafile/table的功能,非常麻烦,该方案也否决掉了。
- 由于variable extent的存在,考虑修改“_asm_rebalance_plan_size”为1,再次发起rebalance尝试,该方案待定,因为会导致rebalance很慢。
- 由于该磁盘组非常大,磁盘比较多,手动发起rebalance,怀疑在rebalance PST repartner阶段仅仅是进行微调,所以考虑使用之前分析问题用过的一个内部event 15195事件设置level 57,15195是一个非常有用debug的event,通常是oracle研发使用的,所以官方并未公开该event的详细用法,我也仅仅只知道level 604和level 57,本次使用的level 57的含义是完全重建磁盘之间的partner关系。
最终裁定的方案就是recreate pst partner,再次发起rebalance,观察磁盘间的最大extent和au差距正在减少,说明这次是有效果的。
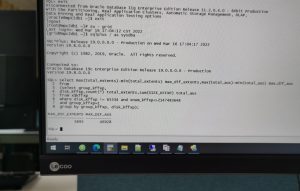
回顾整个故障,得到了一些启发:
- 尽量不使用bigfile
- 对于asm磁盘组剩余空间的监控,必须加上每块磁盘的free_mb监控和磁盘组使用是否均衡的监控,如果及早发现,也不会跟这次一样在比较大的压力下去分析和处理问题
- 不要创建如此大的磁盘组,一个磁盘组内不要使用如此多的磁盘,避免ASM在涉及元数据的一些内部操作时出现紊乱,比如此次的rebalance